Joan Charmant



Blog
- Kinovea 0.9.2
- More VR painting experiments
- Kinovea 0.9.1
- Kinovea 0.8.27
- Turning real scenes into VR paintings
- Kinovea 0.8.26
- Micro-quadcopter using Runcam Split FPV/HD camera
- Down the 4D rabbit hole: Navigation
- .NET library for CardboardCamera's .vr.jpg files
- Kinovea 0.8.25
- Work in progress: light field rendering in VR
- Capsule: omnidirectional stereoscope for Oculus Rift
- Implementing a light field renderer
- Sub-frame-accurate synchronization of two USB cameras
- Estimating a camera's field of view
- Review of the ELP-USBFHD01M camera
- Measuring rolling shutter with a strobing LED
Web
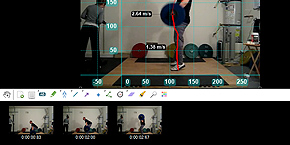 Kinovea: sport motion analysis
Kinovea: sport motion analysis Image remixes (2004-2011)
Image remixes (2004-2011)Bio
 About me
About me{kind=link}